






DeepSeek持续火爆,多个云平台上线相关模型“抢食”算力需求
- 资讯
- 2025-02-04 19:27:04
- 6
腾讯云、百度智能云、阿里云、火山引擎平台都上线DeepSeek的大模型了。
AI 公司 DeepSeek 旗下大模型 DeepSeek-R1“爆火”后,多个云平台宣布上线 DeepSeek旗下模型。
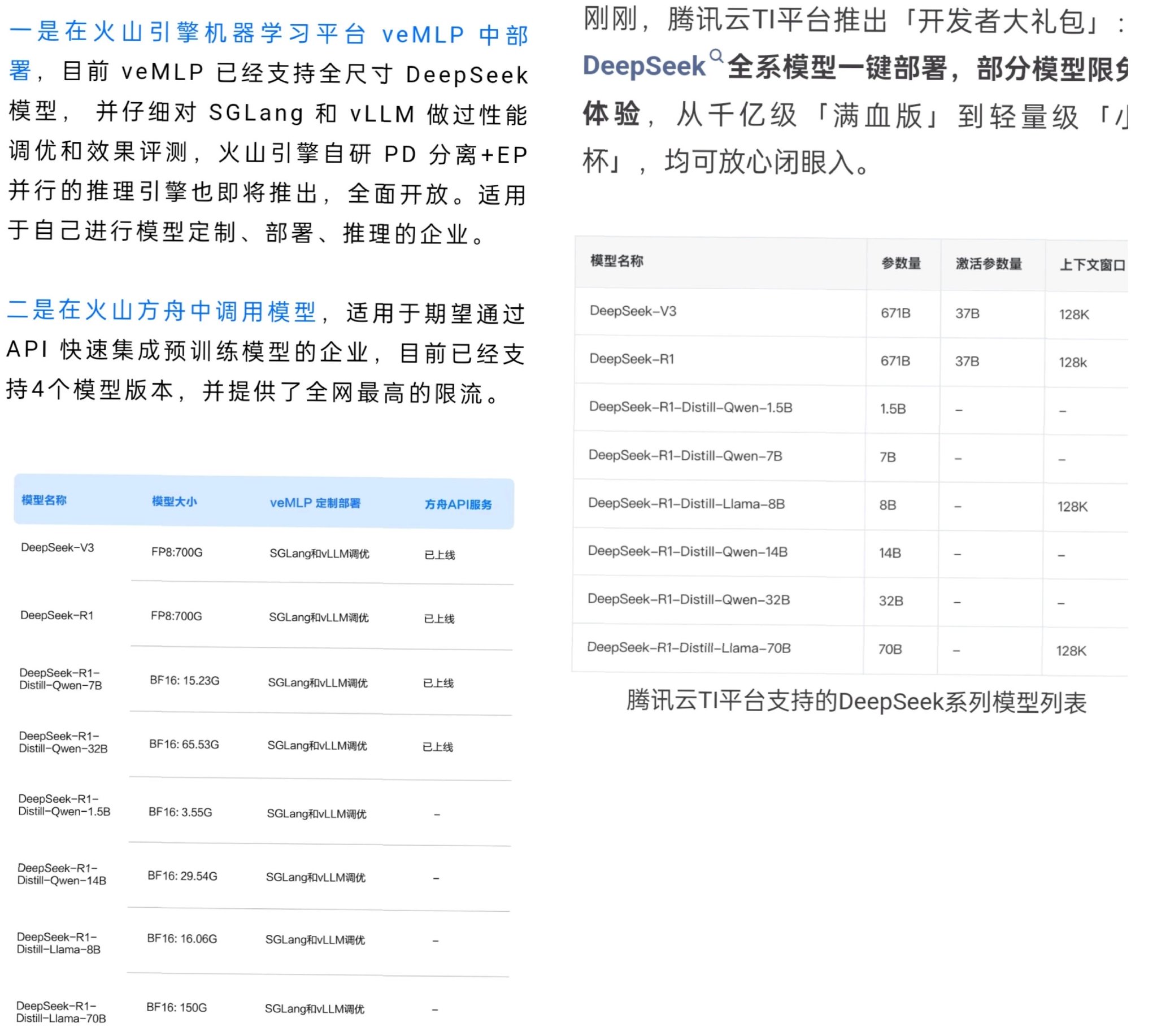
2月4日,火山引擎宣布,将支持 V3、R1 等不同尺寸的 DeepSeek 开源模型,可以通过在火山引擎机器学习平台 veMLP 中部署和在火山方舟中调用模型两种方式使用模型。2月2日,腾讯云宣布腾讯云高性能应用服务 HAI 支持 DeepSeek-R1 一键部署,2月4日又宣布腾讯云 TI上架 DeepSeek系列模型。2月3日晚,百度智能云则宣布,百度智能云千帆平台已正式上架 DeepSeek-R1 和 DeepSeek-V3 模型。阿里云PAI Model Gallery 目前也已经支持 DeepSeek-V3、DeepSeek-R1 以及所有蒸馏小参数模型(DeepSeek-R1-Distill)的一键部署。
DeepSeek-R1 是一款开源模型,也提供了 API(接口)调用方式。据 DeepSeek介绍,DeepSeek-R1 后训练阶段大规模使用了强化学习技术,在只有极少标注数据的情况下提升了模型推理能力,该模型性能对标 OpenAl o1 正式版。DeepSeek-R1 推出后,该模型热度持续攀升。1月 27 日,DeepSeek应用曾登顶苹果中国地区和美国地区应用商店免费 APP 下载排行榜。
面向潜在的算力需求,腾讯云 TI平台上架了"满血"的 V3、R1 原版模型,这两个模型参数量都达到 671B(B 即十亿),并上架了基于 DeepSeek-R1 蒸馏得到的系列模型,参数规模从1.5B到70B不等。腾讯云 TI平台还提供模型服务管理、监控运营、资源伸缩等能力,帮助企业和开发者将 DeepSeek模型接入实际业务。
在这背后,是云厂商们不愿在 DeepSeek的火爆中缺席,卖起了自身的产品、服务以及算力。尽管DeepSeek-R1 是开源模型,但云厂商们在各自平台提供的适配服务,可以让用户更轻松地实现从训练到部署再到推理的全过程,简化模型开发流程,“收拢”部分DeepSeek用户的需求。
记者了解到,目前百度智能云千帆平台上架的DeepSeek-R1和 DeepSeek-V3模型则已全面融合千帆推理链路,集成百度独家内容安全算子,实现模型安全增强与企业级高可用保障,同时支持完善的BLS日志分析和BCM告警。
阿里云也面向开发者提供了蒸馏过后的DeepSeek-R1-Distill-Qwen-7B模型,基于 DeepSeek-R1 的推理能力,通过蒸馏技术将推理模式迁移到较小的 Qwen (通义)模型上,以便更高性价比地实现DeepSeek系列模型与现有业务的高效融合。阿里云相关人士对记者表示,部署DeepSeek-R1-Distill-Qwen-7B模型的价格约为11.1元/小时(以A10机型为例,其余机型的价格参考阿里云官网);部署DeepSeek-R1模型的价格约为316元/小时。
同时,不少云厂商都给出了低于DeepSeek官方刊例价的折扣。目前,DeepSeek-R1的官方刊例价为输入4元/M tokens,输出16元/M tokens,DeepSeek-V3的官方刊例价为输入2元/M tokens,输出8元/M tokens。记者从百度云了解到,百度云上架的对应模型调用价格为DeepSeek-V3官方刊例价的3折、DeepSeek-R1官方刊例价的5折,并提供限时2周的免费服务。阿里云百炼上架的DeepSeek-R1和DeepSeek-V3也宣布限时免费。火山引擎也在公开信息中表示,通过全栈自研推理系统对 DeepSeek 的优化和降本,火山引擎为通过方舟调用 DeepSeek 模型 API 的企业提供有竞争力的价格,并提供全网最高的限流。
值得一提的是,2024年,DeepSeek-V2的发布曾引发了一轮大模型价格战,字节、百度、腾讯、阿里等大模型厂商都曾跟进降价。如今,有“AI界拼多多”之称的DeepSeek是否会掀起大模型的下一轮价格战受到业界关注。
业界对大模型价格竞争已有预期。今年1月,腾讯集团副总裁、政企业务总裁李强在接受第一财经等媒体采访时表示,价格变化如果不是基于技术创新就很难长期持续,腾讯对低效率的纯粹价格竞争未必完全认同,预计2025年传统云计算领域的价格竞争会趋缓,但与大模型相关的部分还是会有价格竞争。
而云平台积极上线DeepSeek旗下模型背后,更深层次的行业变化是,大模型算力需求正在经历变迁。DeepSeek被认为正在探索压缩大模型训练成本,其备受关注的DeepSeek-R1更偏重推理部分。DeepSeek曾公开DeepSeek-V3的训练预算为“2048个GPU、2个月、近600万美元”,外界认为DeepSeek-R1训练成本可能也偏低。这或许意味着,大模型训练不一定能为云厂商持续带来大量算力需求,但开发者部署偏重推理的大模型,可能会为云厂商带来更多算力需求。
李强表示,大模型本身带来的收入占整体市场的规模还比较小,但长期看,大模型行业化应用将更多带来推理相关的计算需求。随着越来越多企业用户和创业公司转向大模型应用,预计应用爆发将带来大量推理需求。
相关文章
热门文章

最准一肖一码100%准,埋伏精选答案落实_手机端862.43
2024-12-27公安局副局长导演假立功,干部醉驾引发争议
2024-12-25白小姐三肖三码必开一码开奖,窃视精选解释落实_ios93.58.89
2024-12-27香港出码综合走势图,代劳精选解释落实_The56.43.44
2024-12-27香港内部马料免费资料亮点,小节精选解释落实_iPhone91.81.51
2024-12-27香港最准最快的资料免费 ,淘气精选答案落实_制作版8.8
2024-12-27
2024年预算:财政大臣雷切尔·里夫斯将向遭受危机打击的NHS注入数十亿美元,以削减等候名单
2024-12-25
美国对以色列宣布杀害辛瓦尔表示欢迎,呼吁加沙“第二天”
2024-12-20
有话要说...